The Seed-First Pivot: Moving Beyond Text-Only Prompts for Consistent Motion

In this article
The initial excitement of typing a sentence and receiving a five-second clip is beginning to wear off for serious creators. We have moved past the novelty phase of generative media. For indie makers and content operators, the “magic box” approach—where you input a vague prompt and hope for the best—is increasingly seen as a liability. It is a workflow defined by gambling rather than craft. To produce professional-grade assets, the methodology must shift from pure text-to-video toward a “seed-first” or “asset-first” workflow.
This pivot recognizes that the text prompt is often the weakest link in the chain of production. While large language models are excellent at interpreting intent, they are notoriously poor at conveying specific spatial relationships, subtle lighting transitions, and physical weight. To solve for this, creators are turning to structured iteration loops that prioritize source images and technical parameters over descriptive adjectives.
The Illusion of Control in Text-to-Video
When you use an AI Video Generator for the first time, the natural instinct is to load the prompt with descriptors: “cinematic,” “hyper-realistic,” “4k,” and “highly detailed.” In practice, these terms are often noise. Most high-end models are already trained on high-quality aesthetics; telling a model to be “cinematic” is like telling a professional cinematographer to “make it look good.” It doesn’t provide actionable data for the diffusion process.
The real challenge in text-only generation is temporal consistency. A prompt can describe a character, but it rarely successfully describes how that character’s face should move across 120 frames without morphing into someone else. This is where the text-to-video pipeline often breaks down. If your prompt is the only thing guiding the generation, the model has too much freedom to hallucinate. This freedom is the enemy of consistency.
The Image-to-Video Anchor
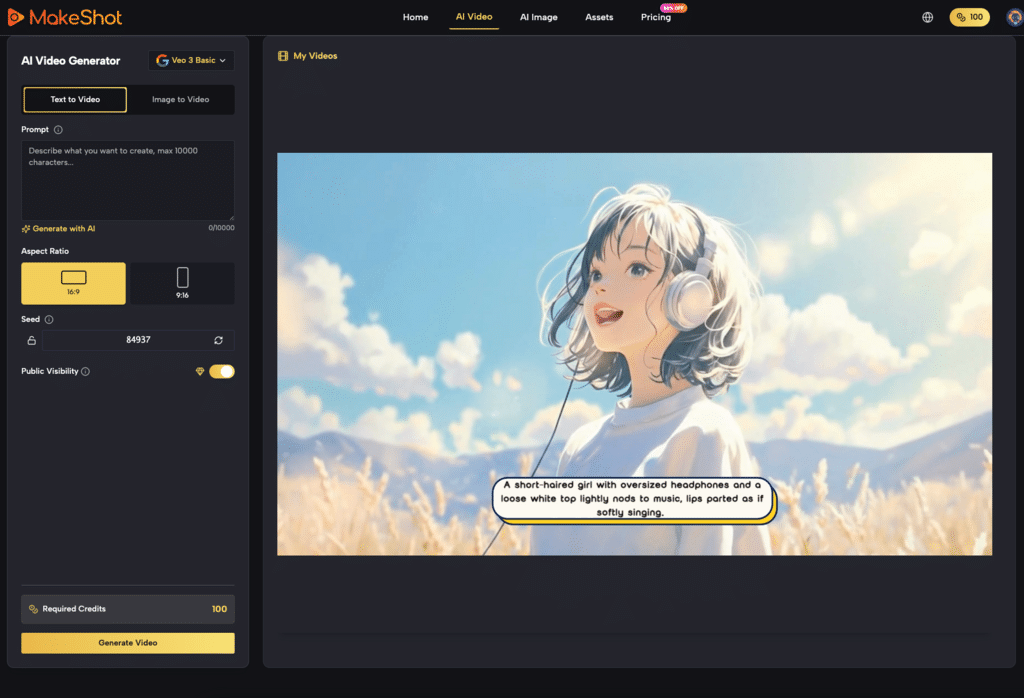
The most significant shift in the current workflow is the move toward Image-to-Video (I2V). By providing a source asset—a high-resolution still image—you effectively lock in the composition, the character design, and the lighting. The AI Video Generator is then tasked only with calculating motion, rather than inventing the entire universe from scratch.
This approach changes the role of the prompt. In an I2V workflow, your prompt should not describe the subject (which the model can already see in the image) but should instead describe the kinetic energy of the scene. Instead of “a woman standing in a neon-lit street,” your prompt becomes “subtle hair blowing in the wind, neon lights flickering in the background, slow zoom-in.” This clarity reduces the computational load on the model’s “imagination” and focuses it on the physics of the movement.
However, even with a strong source image, there is a visible limitation in how current models handle complex interactions. For example, if you provide an image of a person picking up a cup, the AI often struggles with the “collision” between the hand and the object. We are not yet at a point where the AI understands the weight of objects or the resistance of surfaces perfectly.
Mastering the Iteration Loop
Professional creators do not expect a “one-and-done” result. They operate in loops. A typical iteration might look like this:
- Static Generation: Generate a high-fidelity image using a model like Flux or Midjourney to establish the visual “truth” of the project.
- Initial Motion Test: Upload the image to the video generator with a basic motion prompt and a medium “motion bucket” or “motion brush” setting.
- Seed Analysis: If the motion is correct but the quality is low, or if the subject morphs, the creator examines the seed.
- Parameter Tuning: Adjusting the “Motion Strength” or “Visual Content Weight.” If the video drifts too far from the original image, the weight must be increased.
This process requires a level of patience that many new users lack. It is common to run 10 or 20 variations of the same five-second clip, tweaking only a single variable—like the seed or the camera motion intensity—each time. This is not a failure of the tool; it is the nature of working with probabilistic systems. You are not “ordering” a video; you are “herding” the pixels toward a specific outcome.
Refining the Motion Prompt
One of the most effective ways to improve output quality is to learn the “language of the camera.” Generative models respond better to technical film terminology than to flowery prose. Using terms like “dolly zoom,” “low-angle pan,” “handheld shake,” or “rack focus” provides the model with a clear mathematical framework for how pixels should shift relative to each other.
There is, however, an inherent uncertainty in how different models interpret these terms. A “slow pan” in Runway might look very different from a “slow pan” in Kling or Luma. This lack of standardization is one of the primary hurdles for creators. Until there is a unified “motion language” across the industry, the operator must remain tool-agnostic, testing the same prompt across multiple models to see which one “understands” the specific physics of that scene.
Evaluating Model Strengths and Weaknesses
Not all video engines are created equal, and the “best” tool depends entirely on the specific shot required. Some models excel at human anatomy and facial expressions but fail at grand architectural pans. Others can handle complex fluid dynamics—like splashing water or rising smoke—but struggle to keep a character’s clothing consistent.
On platforms like MakeShot, creators have the advantage of accessing multiple “engines” under one roof. This allows for a comparative workflow. For instance, you might find that Google’s Veo handles stylized, vibrant colors with high fidelity, while a model like Kling might be better for realistic human movement. A practical creator will often “round-trip” their assets: generating a base layer in one model, then using the last frame of that video as a starting point for the next segment in a different model.
This modularity is key. We are seeing a move away from “all-in-one” generation toward a pipeline where the creator acts as a director, selecting the right “performer” (model) for the right “scene.”
Managing Expectation and Physical Reality
It is important to reset expectations regarding AI physics. Even with the most advanced prompts and source assets, AI video generators frequently fail at basic “cause and effect” logic. If a character walks through a door, the door might disappear. If they stir a cup of coffee, the spoon might merge with the liquid.
These are not just “bugs”; they are fundamental characteristics of how these models work. They don’t have a 3D model of the world in their “heads”; they have a statistical map of what pixels usually do. As a creator, your job is often to work around these limitations by choosing camera angles that hide these “collision” zones or by using shorter clips that don’t give the AI enough time to lose the architectural integrity of the scene.
The Future of the Prompt-First Creator
The role of the prompt is evolving from a descriptive tool to a steering mechanism. In the near future, we will likely see less reliance on “magic words” and more reliance on “control signals”—depth maps, wireframes, and motion vectors that we provide alongside our prompts.
Until then, the most successful indie makers will be those who stop treating the AI video generator as a search engine for videos they want to find. Instead, they will treat it as a highly sophisticated, somewhat erratic digital puppet. Success in this field requires a disciplined approach to source assets, a technical understanding of camera movement, and the willingness to discard dozens of “almost-perfect” generations in favor of the one that actually holds its shape.
The “Seed-First Pivot” isn’t just a technical change; it’s a professional one. It marks the transition from being a “prompter” to being an operator who understands the mechanics of the medium. By anchoring generations in high-quality source images and iterating with technical precision, you move the output from “random AI art” to a deliberate, professional asset.
Related: Top 5 AI Video Enhancers to Improve Video Quality: Pros & Cons


